

Add files using upload-large-folder tool
Browse files- README.md +151 -8
- data/train-1731264974453484.parquet +3 -0
- figures/distributions.png +3 -0
- figures/rig.png +3 -0
- quickstart.ipynb +74 -0
- shards/train/1731264974453484/1731264974453484-0000.tar +3 -0
- shards/train/1731264974453484/1731264974453484-0001.tar +3 -0
- shards/train/1731264974453484/1731264974453484-0002.tar +3 -0
- shards/train/1731264974453484/1731264974453484-0003.tar +3 -0
- shards/train/1731264974453484/1731264974453484-0004.tar +3 -0
- shards/train/1731264974453484/1731264974453484-0005.tar +3 -0
- shards/train/1731264974453484/1731264974453484-0006.tar +3 -0
- shards/train/1731264974453484/1731264974453484-0007.tar +3 -0
- shards/train/1731264974453484/1731264974453484-0008.tar +3 -0
- shards/train/1731264974453484/1731264974453484-0009.tar +3 -0
- shards/train/1731264974453484/1731264974453484-0010.tar +3 -0
README.md
CHANGED
|
@@ -2,17 +2,160 @@
|
|
| 2 |
license: fair-noncommercial-research-license
|
| 3 |
pretty_name: Ego-1K
|
| 4 |
size_categories:
|
| 5 |
-
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 6 |
---
|
| 7 |
|
| 8 |
-
# Ego-1K
|
| 9 |
|
| 10 |
-
We present Ego-1K, a large-scale, time-synchronized collection of egocentric multiview videos designed to advance neural 3D video synthesis,
|
| 11 |
-
dynamic scene understanding, and embodied perception. The dataset contains 956 short (
|
| 12 |
-
12 synchronous cameras surrounding a VR headset worn by the user, for a total of
|
| 13 |
-
motions and hand-object interactions in different settings. Our dataset enables new ways to benchmark egocentric scene reconstruction methods,
|
| 14 |
-
and presents unique challenges for existing 3D and 4D novel view synthesis methods due to high disparities and image motion caused by close
|
| 15 |
dynamic objects and rig egomotion.
|
| 16 |
|
| 17 |
|
| 18 |
-
 egocentric videos taken with a custom rig with
|
| 28 |
+
12 synchronous cameras surrounding a VR headset worn by the user, for a total of 491K frames and 5.9M images. Scene content focuses on hand
|
| 29 |
+
motions and hand-object interactions in different settings. Our dataset enables new ways to benchmark egocentric scene reconstruction methods,
|
| 30 |
+
and presents unique challenges for existing 3D and 4D novel view synthesis methods due to high disparities and image motion caused by close
|
| 31 |
dynamic objects and rig egomotion.
|
| 32 |
|
| 33 |
|
| 34 |
+

|
| 35 |
+
|
| 36 |
+
## Getting Started
|
| 37 |
+
|
| 38 |
+
See [`quickstart.ipynb`](quickstart.ipynb) for a runnable walkthrough that loads metadata, streams images, and visualizes a 12-camera multiview frame.
|
| 39 |
+
|
| 40 |
+
## Key Statistics
|
| 41 |
+
|
| 42 |
+
| Property | Value |
|
| 43 |
+
|----------|-------|
|
| 44 |
+
| Total recordings | 956 |
|
| 45 |
+
| Train split | 860 recordings |
|
| 46 |
+
| Test split | 96 recordings |
|
| 47 |
+
| Duration per recording | 6.7-9.7 seconds at 60 Hz |
|
| 48 |
+
| Frames per recording | 404-583 (mean 514, median 530) |
|
| 49 |
+
| Cameras | 12 (6 rectified stereo pairs) |
|
| 50 |
+
| Image resolution | 1280 x 1280 pixels (rectified pinhole, 120 deg HFOV) |
|
| 51 |
+
| Total frames | 490,966 |
|
| 52 |
+
| Total images | 5,891,592 |
|
| 53 |
+
| Total duration | 2.3 hours |
|
| 54 |
+
| Total shards | 10,216 |
|
| 55 |
+
| Total dataset size | ~11 TB (WebDataset tar shards) |
|
| 56 |
+
| Typical shard size | ~1.5 GB |
|
| 57 |
+
|
| 58 |
+

|
| 59 |
+
|
| 60 |
+
## Dataset Structure
|
| 61 |
+
|
| 62 |
+
```text
|
| 63 |
+
ego-1k/
|
| 64 |
+
├── data/
|
| 65 |
+
│ ├── train-<scene_id>.parquet # Per-scene metadata index
|
| 66 |
+
│ └── test-<scene_id>.parquet
|
| 67 |
+
└── shards/
|
| 68 |
+
├── train/
|
| 69 |
+
│ └── <scene_id>/
|
| 70 |
+
│ ├── <scene_id>-0000.tar # WebDataset tar shards (~1.5 GB each)
|
| 71 |
+
│ ├── <scene_id>-0001.tar
|
| 72 |
+
│ └── ...
|
| 73 |
+
└── test/
|
| 74 |
+
└── <scene_id>/
|
| 75 |
+
└── <scene_id>-0000.tar
|
| 76 |
+
```
|
| 77 |
+
|
| 78 |
+
### Tar Shard Contents
|
| 79 |
+
|
| 80 |
+
Each tar sample represents one frame across all 12 cameras:
|
| 81 |
+
|
| 82 |
+
```text
|
| 83 |
+
<scene_id>/<frame_id:06d>.200-1.png # Raw PNG bytes (1280x1280)
|
| 84 |
+
<scene_id>/<frame_id:06d>.200-2.png
|
| 85 |
+
...
|
| 86 |
+
<scene_id>/<frame_id:06d>.200-12.png
|
| 87 |
+
<scene_id>/<frame_id:06d>.metadata.json # Pose, rig calibration, scene info
|
| 88 |
+
```
|
| 89 |
+
|
| 90 |
+
The `metadata.json` per sample contains:
|
| 91 |
+
|
| 92 |
+
| Field | Type | Description |
|
| 93 |
+
|-------|------|-------------|
|
| 94 |
+
| `scene_id` | string | Recording identifier |
|
| 95 |
+
| `frame_id` | int | Frame index (0-indexed) |
|
| 96 |
+
| `timestamp_ns` | int | Frame timestamp in nanoseconds |
|
| 97 |
+
| `pose` | list | 4x4 device-to-world transform (key absent if unavailable) |
|
| 98 |
+
| `rig_calibration` | object | Per-camera intrinsics (`K`) and extrinsics (`E`) |
|
| 99 |
+
| `source` | string | Capture campaign: `OVD_M1` (lab, 513 recordings), `OVD_M2` (apartment, 414), `DD4` (29) |
|
| 100 |
+
| `lux_bins` | string | Lighting level: `51-75`, `76-100`, `101-200`, `201-400`, `401-1000`, `1001+` |
|
| 101 |
+
| `tags` | list | Scene diversity tags |
|
| 102 |
+
|
| 103 |
+
## Parquet Schema
|
| 104 |
+
|
| 105 |
+
Each row represents a single frame (one timestamp across all 12 cameras):
|
| 106 |
+
|
| 107 |
+
| Column | Type | Description |
|
| 108 |
+
|--------|------|-------------|
|
| 109 |
+
| `scene_id` | string | Recording identifier |
|
| 110 |
+
| `frame_id` | int32 | Frame index within the recording (0-indexed; number of frames varies per scene, range 404-583) |
|
| 111 |
+
| `timestamp_ns` | int64 | Frame timestamp in nanoseconds |
|
| 112 |
+
| `source` | string | Capture campaign: `OVD_M1` (lab), `OVD_M2` (apartment), `DD4` |
|
| 113 |
+
| `lux_bins` | string | Lighting level: `51-75`, `76-100`, `101-200`, `201-400`, `401-1000`, `1001+` |
|
| 114 |
+
| `tags` | string | JSON list of scene diversity tags (85 unique tags covering garments, furnishings, lighting, pose, objects) |
|
| 115 |
+
| `shard_name` | string | Relative path to the tar shard containing this frame's images (e.g., `shards/train/<scene_id>/<scene_id>-0002.tar`) |
|
| 116 |
+
| `pose` | string | JSON: 4x4 device-to-world transform matrix for this frame (null if pose unavailable) |
|
| 117 |
+
| `rig_calibration` | string | JSON: per-camera intrinsics (`K`: 3x3) and extrinsics (`E`: 4x4), static per scene (repeated for each frame for convenience) |
|
| 118 |
+
|
| 119 |
+
### Calibration Details
|
| 120 |
+
|
| 121 |
+
The `rig_calibration` column contains a JSON object keyed by camera name (`200-1` through `200-12`), each with:
|
| 122 |
+
- **`K`**: 3x3 intrinsic matrix (rectified pinhole projection, 120 deg horizontal FOV)
|
| 123 |
+
- **`E`**: 4x4 extrinsic matrix (camera-to-device transform)
|
| 124 |
+
|
| 125 |
+
The `pose` column contains the 4x4 device-to-world transform, which changes per frame as the headset moves.
|
| 126 |
+
|
| 127 |
+
## Usage
|
| 128 |
+
|
| 129 |
+
`load_dataset` returns frame-level **metadata only** (poses, calibration, scene info). Images are stored in WebDataset tar shards — use the `webdataset` library to stream them. See [`quickstart.ipynb`](quickstart.ipynb) for a full working example.
|
| 130 |
+
|
| 131 |
+
### WebDataset (Recommended for Training)
|
| 132 |
+
|
| 133 |
+
Stream tar shards for high-throughput sequential access — no per-file API calls. See the notebook for the full `decode_sample` implementation. To wrap it in a PyTorch DataLoader:
|
| 134 |
+
|
| 135 |
+
```python
|
| 136 |
+
dataset = wds.WebDataset(shard_urls, nodesplitter=wds.split_by_node, shardshuffle=True).map(decode_sample)
|
| 137 |
+
loader = torch.utils.data.DataLoader(dataset, batch_size=4, num_workers=4)
|
| 138 |
+
|
| 139 |
+
for batch in loader:
|
| 140 |
+
images = batch["images"] # (B, N_cams, 3, 1280, 1280)
|
| 141 |
+
break
|
| 142 |
+
```
|
| 143 |
+
|
| 144 |
+
### Parquet Metadata (Random Access)
|
| 145 |
+
|
| 146 |
+
The Parquet files contain frame-level metadata only (poses, calibration, scene info) — images are stored in the tar shards. Use the `shard_name` column to locate which tar file contains a given frame's images.
|
| 147 |
+
|
| 148 |
+
```python
|
| 149 |
+
shard_url = f"https://huggingface.co/datasets/facebook/ego-1k/resolve/main/{example['shard_name']}"
|
| 150 |
+
```
|
| 151 |
+
|
| 152 |
+
## Citation
|
| 153 |
+
|
| 154 |
+
```bibtex
|
| 155 |
+
@inproceedings{ego1k2026,
|
| 156 |
+
title={{Ego-1K}: A Large-Scale Multiview Video Dataset for Egocentric Vision},
|
| 157 |
+
author={Jae Yong Lee and Daniel Scharstein and Akash Bapat and Hao Hu and Andrew Fu and Haoru Zhao and Paul Sammut and Xiang Li and Stephen Jeapes and Anik Gupta and Lior David and Saketh Madhuvarasu and Jay Girish Joshi and Jason Wither},
|
| 158 |
+
booktitle={CVPR},
|
| 159 |
+
year={2026}
|
| 160 |
+
}
|
| 161 |
+
```
|
data/train-1731264974453484.parquet
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:13763e5c941beb67c4c9d6fb1497992971e793519a6e751fb8f5137ee03bfc01
|
| 3 |
+
size 72238
|
figures/distributions.png
ADDED

|
Git LFS Details
|
figures/rig.png
ADDED
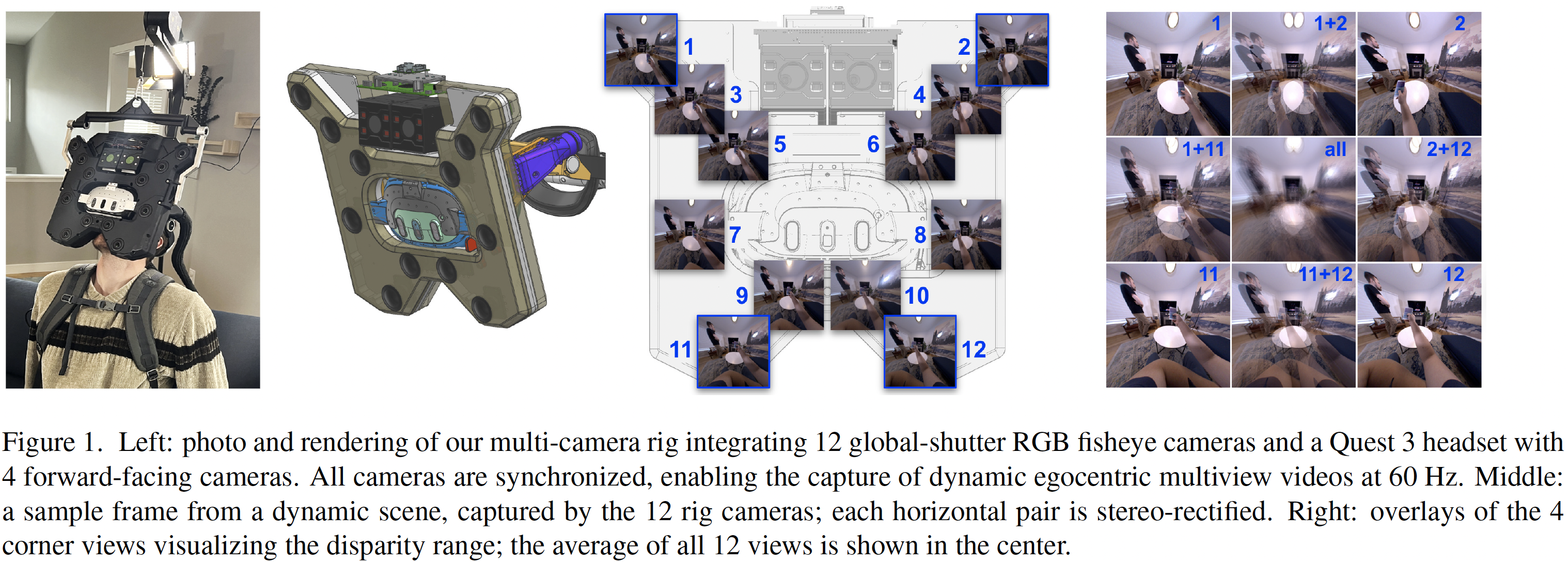
|
Git LFS Details
|
quickstart.ipynb
ADDED
|
@@ -0,0 +1,74 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "markdown",
|
| 5 |
+
"metadata": {},
|
| 6 |
+
"source": "# Ego-1K Quickstart\n\nThis notebook demonstrates how to load and explore the [Ego-1K](https://huggingface.co/datasets/facebook/ego-1k) dataset — a large-scale, time-synchronized collection of egocentric multiview videos with 12 cameras, 956 recordings, and ~491K frames.\n\n**What you'll learn:**\n1. Load frame-level metadata (poses, calibration, scene info) from Parquet\n2. Parse rig calibration and device pose\n3. Stream images from WebDataset tar shards\n4. Visualize a multiview frame (12 cameras)\n\n**Prerequisites:**\n```bash\npip install datasets webdataset torch numpy Pillow huggingface_hub matplotlib\n```"
|
| 7 |
+
},
|
| 8 |
+
{
|
| 9 |
+
"cell_type": "code",
|
| 10 |
+
"execution_count": null,
|
| 11 |
+
"metadata": {},
|
| 12 |
+
"outputs": [],
|
| 13 |
+
"source": "import io\nimport json\n\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport torch\nimport webdataset as wds\nfrom datasets import load_dataset\nfrom huggingface_hub import HfApi\nfrom PIL import Image\n\nREPO_ID = \"facebook/ego-1k\"\nCAMERAS = [f\"200-{i}\" for i in range(1, 13)] # 12 cameras"
|
| 14 |
+
},
|
| 15 |
+
{
|
| 16 |
+
"cell_type": "code",
|
| 17 |
+
"execution_count": null,
|
| 18 |
+
"metadata": {},
|
| 19 |
+
"outputs": [],
|
| 20 |
+
"source": "# Load frame-level metadata from Parquet (no images downloaded)\nds = load_dataset(REPO_ID, split=\"test\")\nprint(f\"{len(ds)} frames, columns: {ds.column_names}\")\n\nexample = ds[0]\nprint(f\"Example: scene={example['scene_id']}, frame={example['frame_id']}, \"\n f\"source={example['source']}, lux={example['lux_bins']}\")"
|
| 21 |
+
},
|
| 22 |
+
{
|
| 23 |
+
"cell_type": "code",
|
| 24 |
+
"execution_count": null,
|
| 25 |
+
"metadata": {},
|
| 26 |
+
"outputs": [],
|
| 27 |
+
"source": "# Parse rig calibration and device pose from one example\nrig = json.loads(example[\"rig_calibration\"])\npose = json.loads(example[\"pose\"]) if example[\"pose\"] else None\n\nK = np.array(rig[\"200-1\"][\"K\"])\nE = np.array(rig[\"200-1\"][\"E\"])\nprint(f\"Cameras: {sorted(rig.keys())}\")\nprint(f\"Intrinsics K: {K.shape}, Extrinsics E: {E.shape}\")\nif pose is not None:\n print(f\"Device pose: {np.array(pose).shape}\")"
|
| 28 |
+
},
|
| 29 |
+
{
|
| 30 |
+
"cell_type": "code",
|
| 31 |
+
"execution_count": null,
|
| 32 |
+
"metadata": {},
|
| 33 |
+
"outputs": [],
|
| 34 |
+
"source": "def decode_wds_sample(sample, cameras):\n \"\"\"Decode a WebDataset sample into images, intrinsics, extrinsics, and pose.\"\"\"\n meta = json.loads(sample[\"metadata.json\"])\n rig = meta[\"rig_calibration\"]\n\n images, intrinsics, extrinsics = [], [], []\n for cam in cameras:\n img = Image.open(io.BytesIO(sample[f\"{cam}.png\"])).convert(\"RGB\")\n img_tensor = torch.from_numpy(np.array(img)).permute(2, 0, 1).float() / 255.0\n images.append(img_tensor)\n intrinsics.append(torch.tensor(rig[cam][\"K\"], dtype=torch.float32))\n extrinsics.append(torch.tensor(rig[cam][\"E\"], dtype=torch.float32))\n\n pose_raw = meta.get(\"pose\")\n pose = (\n torch.tensor(pose_raw, dtype=torch.float32)\n if pose_raw is not None\n else torch.zeros(4, 4)\n )\n\n return {\n \"images\": torch.stack(images),\n \"intrinsics\": torch.stack(intrinsics),\n \"extrinsics\": torch.stack(extrinsics),\n \"pose\": pose,\n \"scene_id\": meta[\"scene_id\"],\n \"frame_id\": meta[\"frame_id\"],\n }\n\n\n# Discover tar shards for the test split\napi = HfApi()\nall_files = api.list_repo_files(repo_id=REPO_ID, repo_type=\"dataset\")\nshard_files = sorted(\n f for f in all_files if f.startswith(\"shards/test/\") and f.endswith(\".tar\")\n)\n\n# Stream one frame from the first shard (each shard is ~1.5 GB)\nshard = shard_files[0]\nbase_url = f\"https://huggingface.co/datasets/{REPO_ID}/resolve/main\"\nshard_url = f\"pipe:curl -sfL '{base_url}/{shard}'\"\n\npipeline = wds.WebDataset(\n [shard_url], nodesplitter=wds.split_by_node, shardshuffle=False\n).map(lambda s: decode_wds_sample(s, CAMERAS))\n\nsample = next(iter(pipeline))\nprint(f\"scene={sample['scene_id']}, frame={sample['frame_id']}, \"\n f\"images={sample['images'].shape}\")"
|
| 35 |
+
},
|
| 36 |
+
{
|
| 37 |
+
"cell_type": "code",
|
| 38 |
+
"execution_count": null,
|
| 39 |
+
"metadata": {},
|
| 40 |
+
"outputs": [],
|
| 41 |
+
"source": [
|
| 42 |
+
"# Visualize all 12 camera views from the streamed frame\n",
|
| 43 |
+
"fig, axes = plt.subplots(2, 6, figsize=(24, 8))\n",
|
| 44 |
+
"fig.suptitle(\n",
|
| 45 |
+
" f\"Ego-1K — Scene {sample['scene_id']}, Frame {sample['frame_id']}\",\n",
|
| 46 |
+
" fontsize=14,\n",
|
| 47 |
+
")\n",
|
| 48 |
+
"\n",
|
| 49 |
+
"for idx, ax in enumerate(axes.flat):\n",
|
| 50 |
+
" # Convert from (C, H, W) float tensor to (H, W, C) numpy for display\n",
|
| 51 |
+
" img = sample[\"images\"][idx].permute(1, 2, 0).numpy()\n",
|
| 52 |
+
" ax.imshow(img)\n",
|
| 53 |
+
" ax.set_title(CAMERAS[idx], fontsize=10)\n",
|
| 54 |
+
" ax.axis(\"off\")\n",
|
| 55 |
+
"\n",
|
| 56 |
+
"plt.tight_layout()\n",
|
| 57 |
+
"plt.show()"
|
| 58 |
+
]
|
| 59 |
+
}
|
| 60 |
+
],
|
| 61 |
+
"metadata": {
|
| 62 |
+
"kernelspec": {
|
| 63 |
+
"display_name": "Python 3",
|
| 64 |
+
"language": "python",
|
| 65 |
+
"name": "python3"
|
| 66 |
+
},
|
| 67 |
+
"language_info": {
|
| 68 |
+
"name": "python",
|
| 69 |
+
"version": "3.10.0"
|
| 70 |
+
}
|
| 71 |
+
},
|
| 72 |
+
"nbformat": 4,
|
| 73 |
+
"nbformat_minor": 4
|
| 74 |
+
}
|
shards/train/1731264974453484/1731264974453484-0000.tar
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:06c2176845a98b13c2d83e7a170c57ebb760c45c5b7f084d7c57237e03eb2028
|
| 3 |
+
size 1781473280
|
shards/train/1731264974453484/1731264974453484-0001.tar
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d67ddf3e8afb5d493bf5b29c1788ba3eb3826ffe34ff0838ac02330fc99e3feb
|
| 3 |
+
size 1785630720
|
shards/train/1731264974453484/1731264974453484-0002.tar
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:4ada8961b330e85651316e41a0a6f0bbed7abf21cdb7d231b5e921d01f3abb4a
|
| 3 |
+
size 1785190400
|
shards/train/1731264974453484/1731264974453484-0003.tar
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f3bfa001017a3825898655562a8ec290ed3a2bb7fe823d68dac75d369fdbd77e
|
| 3 |
+
size 1783889920
|
shards/train/1731264974453484/1731264974453484-0004.tar
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:13711ed46e893e01d9839a41f90e1a6d1be071f69033ff8fcdf3307b54db144c
|
| 3 |
+
size 1785774080
|
shards/train/1731264974453484/1731264974453484-0005.tar
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:1d020fa14fd30948e13f890f8dec90b17e29b8b78cbe3849a77b6508ce3e6bdd
|
| 3 |
+
size 1779752960
|
shards/train/1731264974453484/1731264974453484-0006.tar
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:6d021102a56a682c1c3361bb453ee8883fc3c231b7f8643499d1960615038223
|
| 3 |
+
size 1778759680
|
shards/train/1731264974453484/1731264974453484-0007.tar
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c2544553e695dfab9a51641070fe84cbd200d739a6c2686ef8e67a16433d331c
|
| 3 |
+
size 1777100800
|
shards/train/1731264974453484/1731264974453484-0008.tar
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:1db18796dc90d73335341ca18ce85b3754903f3e660dd13d2f1c6f1885a701e7
|
| 3 |
+
size 1778841600
|
shards/train/1731264974453484/1731264974453484-0009.tar
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d9fe6f55b24c36bf1438bd3a53b6219d79fe25986c06a9dc980c96764db41de7
|
| 3 |
+
size 1792399360
|
shards/train/1731264974453484/1731264974453484-0010.tar
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:4ef4423d7b4b97c04a403d489f75323a71da017a5a804a8778253aa9aaa405b8
|
| 3 |
+
size 1589811200
|